
Articles tagged ‘spark’
* Feud.eu – Analysing Twitter hashtags
18. November 2016, Jakub Horák. Categorized as Twitter.
Expanding on the idea of my previous project MrTweety, I wanted to provide better real-time data and also try out big-data processing software. That’s when I discovered Apache Spark, toolbox used to manage distributed batch processing. My chosen project was not too complex, I was thinking of it being more like a proof of concept. The basic idea is to analyze a real-time feed of tweets posted globally on Twitter. From each individual tweet, occurrences of hashtags are counted and summed in 10 second intervals together. From these intervals a 15 minute sliding window is generated and hashtag counts again summed to form the final table. Top five most occurring hashtags are shown as a result.
To start, I checked out the Twitter API and saw that they offer streaming API. After some research, I’ve found an official Twitter Hosebird Client library and an example of how to use it to publish messages to Kafka. Kafka is messaging system that is also a perfect source of data for Spark. That means we have one subproject for taking the Twitter stream and “producing” it into Kafka. A Spark subproject is then receiving the data and processing it. While working with Spark, I got a little derailed, when I found that you can use Twitter receiver directly with Twitter DStream. However when I actually tried this library, it didn’t work. I suspect that the DStream receiver tries to connect and read Twitter API from multiple threads and that forces Twitter to block the connections altogether. The Twitter DStream project got deleted from Github, while I was using it, so I’ve decided to go back to the Kafka approach. The official Hosebird Client claims to implement the limits and backing-off mechanisms correctly, so I believe it’s better anyway.
After that. Spark does all the hard computing work for us. We just specify, what we want to do with the data. Spark is made to be distributed, but for this small example we use just one node. Everything is running on Amazon ECS, which is a nice “Docker as a service” platform. To make it work, we just need an EC2 instance to run the Docker container. The basic t2.micro instance’s 1GB of memory was not enough for the all the included hungry JVMs, so I had to get a “spot instance” m3.medium with 3.75GB RAM. In the current market the costs should be around 7.5$ per month.
I’ve developed the whole project from scratch on Github as open-source, so check it out there. The production site is feud.eu. Here is a screenshot:
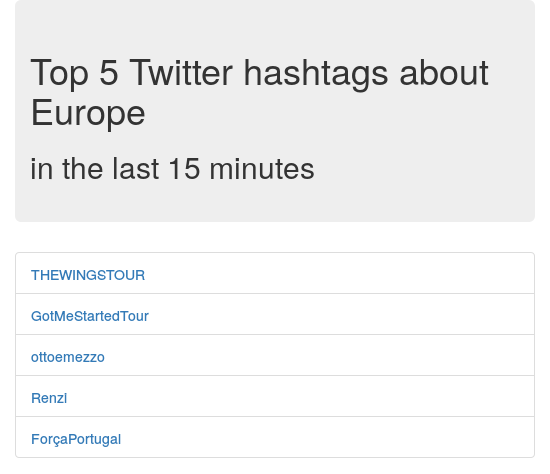
Note: A similar project that I’ve found and that could be interesting to check out is Twitter Analytics with Spark.
* Discovering Akka
25. April 2016, Jakub Horák. Categorized as Frameworks.
I came across this interesting piece of technology called Akka and I’ve decided to write a few words about it. So what is Akka? In short it is a toolkit and runtime for concurrent and distributed applications. To describe in more detail, we have to first talk about the motivation, why would someone use it.
Today we live in the era of distributed systems, billions of people use internet for their everyday life and successful online services have to plan for massive traffic. As soon as a service becomes popular, it is not economically viable to serve it using one large super-computer, but rather use a cluster of cheaper machines. As a programmer, who comes from a Java background, I have implemented concurrent thread-safe programs too many times to know, that it’s not easy. Concurrent systems introduce a new dimension of difficulty. To simplify the concurrent programing and introduce a common standard, company called Lightbend (previously Typesafe) came up with the Reactive manifesto.
Point of the Reactive manifesto is that distributed systems built following it’s guidelines will be easier to develop, scale, maintain and enhance at a later time. They are flexible, loosely-coupled, tolerant of failure and can handle unexpected behavior gracefully. Last but not least they they provide user with interactive responsive feedback.
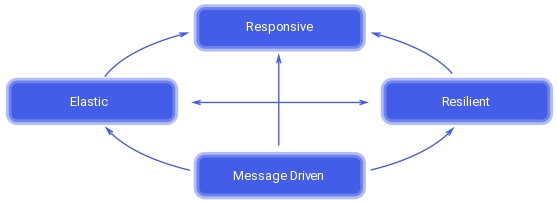
Reactive traits. Arrows show, how they depend on each other.
So what are then the problems of concurrency? Distributed code by default behaves non-deterministically. Without any locking, every time you run the program, you get a different result. It is caused by multiple threads sharing a mutable state, e.g. a common global variable. That leads to race conditions, when things are happening in a different order than the programmer expected. Another problem is thread starvation, when a thread will never get to work and advance the states, because others have higher priority. This happens for example in an OS process scheduler, when there are many processes with high priority and a low priority process will never get to run on CPU.
Akka is a toolkit and runtime for simplifying the construction of concurrent and distributed applications on the JVM. Reasons to write Akka were practical. First simple actor implementation (not yet Akka) was written as a part of Scala in 2006. By 2008 Scala was used in complex server applications and need for a better library support was growing. That motivated developers to come up with Akka. It was released in 2010 and drew inspiration from Erlang’s libraries. Today it is a part of Scala standard library. Java programmers don’t have to be sad though, as there are also language bindings for Java. The library is open-source (Apache License 2.0) and developed by Lightbend, which is well known for its Play framework.
Akka has many features. These are the main ones:
- actor system, which introduces a concept of actor as a unit of execution,
- remoting allows messages to be sent between machines,
- routing defines how are the messages sent to the routees,
- clustering allows cluster nodes to run a part of a bigger application,
- Akka Persistence introduces actors with state, that remains even after restart, and
- Akka Streams provides asynchronous stream processing with non-blocking back pressure.
Actors encapsulate state and behavior. They are isolated and lightweight, meaning that they don’t have hard references to each other, only so called ActorRef. To communicate, they pass serializable messages back and forth. Advantage of this approach is location transparency – actors can communicate locally or over network, it’s only a matter of configuration. Akka is distributed by default, meaning you can only pass messages and everything is asynchronous. It hides all thread-related code behind its actor model and allows programmers to write code easily scalable and fault-tolerant.
We already mentioned you can use Akka in Java. To do that, you just have to make sure that all messages are immutable and serializable, because they could be sent over network. Immutability is achieved in Java by making all attributes final. Akka also requires toString(), equals() and hashCode() methods to be implemented.
When building reactive applications in Java, it is often convenient to use Lambdas. Lambdas are small blocks of code, that can be executed in separate threads. Typically these applications use many callbacks and Lambdas make it easy to write them. Before Java 8 we had to use inner classes and that was not as nice.
To see how can Akka be used, I recommend trying out these two examples:
https://www.lightbend.com/activator/template/hello-akka-java8
https://www.lightbend.com/activator/template/akka-sample-remote-java
Go to akka.io to read up on the documentation or to lightbend.com/activator/templates for more samples. Also check out Apache Spark, a fast and general engine for large-scale data processing built on Akka or Apache Spark Streaming, which can do the same for near real-time small batches of data.
Archives
- July 2025
- March 2024
- October 2023
- May 2020
- December 2018
- October 2018
- July 2017
- April 2017
- March 2017
- November 2016
- April 2016
- March 2016
- November 2014
- September 2014
- May 2014
- March 2014
- February 2014
- August 2013
- June 2013
- April 2012
- August 2011
- May 2011
- October 2010
- September 2010
- August 2010
- December 2009
- November 2009
- October 2009
- September 2009
- August 2009
- July 2009
- June 2009
- April 2009
- January 2009
- December 2008
- October 2008
- September 2008