
* Feud.eu – Analysing Twitter hashtags
18. November 2016, Jakub Horák. Categorized as Twitter.
Expanding on the idea of my previous project MrTweety, I wanted to provide better real-time data and also try out big-data processing software. That’s when I discovered Apache Spark, toolbox used to manage distributed batch processing. My chosen project was not too complex, I was thinking of it being more like a proof of concept. The basic idea is to analyze a real-time feed of tweets posted globally on Twitter. From each individual tweet, occurrences of hashtags are counted and summed in 10 second intervals together. From these intervals a 15 minute sliding window is generated and hashtag counts again summed to form the final table. Top five most occurring hashtags are shown as a result.
To start, I checked out the Twitter API and saw that they offer streaming API. After some research, I’ve found an official Twitter Hosebird Client library and an example of how to use it to publish messages to Kafka. Kafka is messaging system that is also a perfect source of data for Spark. That means we have one subproject for taking the Twitter stream and “producing” it into Kafka. A Spark subproject is then receiving the data and processing it. While working with Spark, I got a little derailed, when I found that you can use Twitter receiver directly with Twitter DStream. However when I actually tried this library, it didn’t work. I suspect that the DStream receiver tries to connect and read Twitter API from multiple threads and that forces Twitter to block the connections altogether. The Twitter DStream project got deleted from Github, while I was using it, so I’ve decided to go back to the Kafka approach. The official Hosebird Client claims to implement the limits and backing-off mechanisms correctly, so I believe it’s better anyway.
After that. Spark does all the hard computing work for us. We just specify, what we want to do with the data. Spark is made to be distributed, but for this small example we use just one node. Everything is running on Amazon ECS, which is a nice “Docker as a service” platform. To make it work, we just need an EC2 instance to run the Docker container. The basic t2.micro instance’s 1GB of memory was not enough for the all the included hungry JVMs, so I had to get a “spot instance” m3.medium with 3.75GB RAM. In the current market the costs should be around 7.5$ per month.
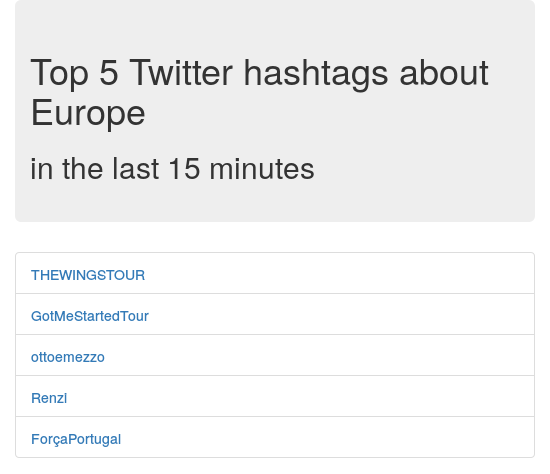
I’ve developed the whole project from scratch on Github as open-source, so check it out there. The production site is feud.eu. Here is a screenshot:
Note: A similar project that I’ve found and that could be interesting to check out is Twitter Analytics with Spark.
Leave a comment
Archives
- July 2025
- March 2024
- October 2023
- May 2020
- December 2018
- October 2018
- July 2017
- April 2017
- March 2017
- November 2016
- April 2016
- March 2016
- November 2014
- September 2014
- May 2014
- March 2014
- February 2014
- August 2013
- June 2013
- April 2012
- August 2011
- May 2011
- October 2010
- September 2010
- August 2010
- December 2009
- November 2009
- October 2009
- September 2009
- August 2009
- July 2009
- June 2009
- April 2009
- January 2009
- December 2008
- October 2008
- September 2008